> ## Documentation Index
> Fetch the complete documentation index at: https://www.krea.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# ChatGPT 1.5
> O modelo de imagem mais preciso da OpenAI, feito para prompts complexos, renderização de texto acurada e edições direcionadas que deixam o resto do quadro intocado.
 ## Visão geral
O mais recente modelo de geração de imagens da OpenAI, baseado no GPT Image 1.5, uma arquitetura nativamente multimodal que processa texto e imagens por uma única rede unificada em vez de tratá-los como sistemas separados. O resultado prático é um modelo que segue instruções complexas com precisão incomum, **lida com renderização densa de texto com precisão** e faz edições direcionadas em imagens sem desestabilizar todo o resto do quadro.
Ele é mais lento e consome mais créditos que os Fast Models, mas para tarefas que exigem aderência exata ao prompt, texto legível dentro de imagens ou edição iterativa controlada, é uma das opções mais capazes na plataforma.
## Começando
1. **Vá para Geração de imagem** — Navegue até [krea.ai/image](https://krea.ai/image) e selecione este modelo no dropdown.
2. **Selecione ChatGPT 1.5** — Abra o seletor de modelos e escolha ChatGPT 1.5 na seção Intelligent Models.
3. **Escreva seu prompt** — Seja o mais específico e descritivo possível. O ChatGPT 1.5 foi feito para seguir instruções precisas, então prompts detalhados produzem resultados perceptivelmente melhores que vagos.
4. **Adicione imagens de referência (opcional)** — Faça upload de imagens para guiar composição, estilo ou tema.
5. **Escolha sua proporção** — Selecione retrato, paisagem ou quadrado dependendo do seu caso de uso.
6. **Gere** — Clique em Generate. O ChatGPT 1.5 é mais lento que os fast models, mas a qualidade da saída reflete o tempo de processamento adicional.
7. **Itere** — Peça mudanças específicas no seu resultado. O ChatGPT 1.5 vai modificar apenas o que você pediu, mantendo o resto da imagem consistente.
## Em resumo
| Recurso | Detalhe |
| ---------------------------------- | ------------------------------------------------------------------- |
| **Velocidade** | Lenta (1/3) |
| **Créditos** | \~150 por geração |
| **Modelo subjacente** | GPT Image 1.5 (OpenAI) |
| **Melhor para** | Prompts complexos, renderização de texto, edição precisa de imagens |
| **Tamanhos suportados** | 1:1 quadrado, 3:2 paisagem, 2:3 retrato |
| **Suporte a referência de estilo** | Sim |
## Quando usar o ChatGPT 1.5
O ChatGPT 1.5 é o modelo certo quando precisão importa mais do que velocidade. Sua arquitetura nativamente multimodal significa que ele entende a relação entre texto e imagem em um nível mais profundo do que a maioria dos modelos, o que se traduz em maior aderência ao prompt e resultados mais confiáveis em solicitações complexas ou em camadas.
Sua capacidade de renderização de texto é particularmente forte. Onde muitos modelos têm dificuldade em produzir texto legível e com ortografia correta dentro de uma imagem, o ChatGPT 1.5 lida com texto denso e em pequena escala com precisão, tornando-o uma opção sólida para qualquer prompt que inclua placas, tipografia, rótulos ou diagramas.
Ele também se destaca em edição iterativa. Quando você pede para mudar uma coisa específica em uma imagem, ele ajusta apenas o que você especificou, preservando semelhança facial, iluminação, composição e tom de cor no restante do quadro. Isso resolve uma das frustrações mais comuns com geração de imagem por IA, em que pedir uma pequena edição faz a imagem inteira ser regenerada do zero.
| Use quando | Evite quando |
| ------------------------------------------------------------------- | ---------------------------------------------------------------------- |
| Seu prompt é complexo e exige interpretação precisa | Você precisa de resultados rápidos ou está em fase inicial de rascunho |
| Sua imagem precisa incluir texto legível | Você está com orçamento apertado de créditos |
| Você precisa fazer edições específicas sem alterar a imagem toda | Você quer uma saída fortemente estilizada ou artística |
| Você está trabalhando em diagramas, personagens ou cenas detalhadas | Você precisa de suporte a estilo LoRA |
| Semelhança facial ou consistência visual entre edições importa | |
## Casos de uso comuns
* **Diagramas e infográficos**: ilustrações técnicas com rótulos e texto precisos
* **Design de personagem**: aparência consistente do personagem em múltiplas iterações
* **Visuais de marketing**: layouts com texto legível, logos ou destaques de produto
* **Edição de fotos**: modificações direcionadas em imagens existentes sem regeneração completa
* **Cenas complexas**: composições multielemento que exigem relações espaciais precisas
## Dicas de prompt
### Escrevendo prompts eficazes
* Escreva prompts como se estivesse dando um briefing criativo detalhado — descreva sujeito, estilo, iluminação, composição e clima explicitamente
* Para texto dentro de imagens, especifique a redação exata, estilo de fonte, tamanho e posicionamento
* Descreva relações espaciais com clareza: "a red mug on the left side of a white table, window light from the right"
* O ChatGPT 1.5 lida bem com prompts longos e detalhados — não abrevie quando puder ser específico
### Iterando nos resultados
* Ao editar, descreva apenas a mudança desejada e deixe tudo o resto sem especificar — o modelo preservará o que você não mencionar
* Para trabalho com personagens, estabeleça a aparência na primeira geração e depois faça referência explícita em edições subsequentes
* Se o resultado não estiver bom, refine a linguagem do prompt em vez de regenerar com o mesmo texto
### Aproveitando ao máximo a renderização de texto
* Coloque qualquer texto que precise aparecer na imagem entre aspas dentro do seu prompt
* Especifique o estilo da fonte se importar: "sans-serif", "handwritten", "bold uppercase"
* Para layouts densos de texto como pôsteres ou diagramas, divida o layout em seções claras no seu prompt
# Exemplos
`A photorealistic night scene on a narrow Barcelona street, warm amber streetlights , Gothic Quarter architecture lining both sides. In the foreground, a small tapas stall with a glowing sign reading "EL RACÓ" in bold yellow letters, a handwritten menu board underneath listing "Patatas Bravas, Croquetas, Pan con Tomate." Locals and tourists passing by, neon signs in Spanish and Catalan in the background.`
## Visão geral
O mais recente modelo de geração de imagens da OpenAI, baseado no GPT Image 1.5, uma arquitetura nativamente multimodal que processa texto e imagens por uma única rede unificada em vez de tratá-los como sistemas separados. O resultado prático é um modelo que segue instruções complexas com precisão incomum, **lida com renderização densa de texto com precisão** e faz edições direcionadas em imagens sem desestabilizar todo o resto do quadro.
Ele é mais lento e consome mais créditos que os Fast Models, mas para tarefas que exigem aderência exata ao prompt, texto legível dentro de imagens ou edição iterativa controlada, é uma das opções mais capazes na plataforma.
## Começando
1. **Vá para Geração de imagem** — Navegue até [krea.ai/image](https://krea.ai/image) e selecione este modelo no dropdown.
2. **Selecione ChatGPT 1.5** — Abra o seletor de modelos e escolha ChatGPT 1.5 na seção Intelligent Models.
3. **Escreva seu prompt** — Seja o mais específico e descritivo possível. O ChatGPT 1.5 foi feito para seguir instruções precisas, então prompts detalhados produzem resultados perceptivelmente melhores que vagos.
4. **Adicione imagens de referência (opcional)** — Faça upload de imagens para guiar composição, estilo ou tema.
5. **Escolha sua proporção** — Selecione retrato, paisagem ou quadrado dependendo do seu caso de uso.
6. **Gere** — Clique em Generate. O ChatGPT 1.5 é mais lento que os fast models, mas a qualidade da saída reflete o tempo de processamento adicional.
7. **Itere** — Peça mudanças específicas no seu resultado. O ChatGPT 1.5 vai modificar apenas o que você pediu, mantendo o resto da imagem consistente.
## Em resumo
| Recurso | Detalhe |
| ---------------------------------- | ------------------------------------------------------------------- |
| **Velocidade** | Lenta (1/3) |
| **Créditos** | \~150 por geração |
| **Modelo subjacente** | GPT Image 1.5 (OpenAI) |
| **Melhor para** | Prompts complexos, renderização de texto, edição precisa de imagens |
| **Tamanhos suportados** | 1:1 quadrado, 3:2 paisagem, 2:3 retrato |
| **Suporte a referência de estilo** | Sim |
## Quando usar o ChatGPT 1.5
O ChatGPT 1.5 é o modelo certo quando precisão importa mais do que velocidade. Sua arquitetura nativamente multimodal significa que ele entende a relação entre texto e imagem em um nível mais profundo do que a maioria dos modelos, o que se traduz em maior aderência ao prompt e resultados mais confiáveis em solicitações complexas ou em camadas.
Sua capacidade de renderização de texto é particularmente forte. Onde muitos modelos têm dificuldade em produzir texto legível e com ortografia correta dentro de uma imagem, o ChatGPT 1.5 lida com texto denso e em pequena escala com precisão, tornando-o uma opção sólida para qualquer prompt que inclua placas, tipografia, rótulos ou diagramas.
Ele também se destaca em edição iterativa. Quando você pede para mudar uma coisa específica em uma imagem, ele ajusta apenas o que você especificou, preservando semelhança facial, iluminação, composição e tom de cor no restante do quadro. Isso resolve uma das frustrações mais comuns com geração de imagem por IA, em que pedir uma pequena edição faz a imagem inteira ser regenerada do zero.
| Use quando | Evite quando |
| ------------------------------------------------------------------- | ---------------------------------------------------------------------- |
| Seu prompt é complexo e exige interpretação precisa | Você precisa de resultados rápidos ou está em fase inicial de rascunho |
| Sua imagem precisa incluir texto legível | Você está com orçamento apertado de créditos |
| Você precisa fazer edições específicas sem alterar a imagem toda | Você quer uma saída fortemente estilizada ou artística |
| Você está trabalhando em diagramas, personagens ou cenas detalhadas | Você precisa de suporte a estilo LoRA |
| Semelhança facial ou consistência visual entre edições importa | |
## Casos de uso comuns
* **Diagramas e infográficos**: ilustrações técnicas com rótulos e texto precisos
* **Design de personagem**: aparência consistente do personagem em múltiplas iterações
* **Visuais de marketing**: layouts com texto legível, logos ou destaques de produto
* **Edição de fotos**: modificações direcionadas em imagens existentes sem regeneração completa
* **Cenas complexas**: composições multielemento que exigem relações espaciais precisas
## Dicas de prompt
### Escrevendo prompts eficazes
* Escreva prompts como se estivesse dando um briefing criativo detalhado — descreva sujeito, estilo, iluminação, composição e clima explicitamente
* Para texto dentro de imagens, especifique a redação exata, estilo de fonte, tamanho e posicionamento
* Descreva relações espaciais com clareza: "a red mug on the left side of a white table, window light from the right"
* O ChatGPT 1.5 lida bem com prompts longos e detalhados — não abrevie quando puder ser específico
### Iterando nos resultados
* Ao editar, descreva apenas a mudança desejada e deixe tudo o resto sem especificar — o modelo preservará o que você não mencionar
* Para trabalho com personagens, estabeleça a aparência na primeira geração e depois faça referência explícita em edições subsequentes
* Se o resultado não estiver bom, refine a linguagem do prompt em vez de regenerar com o mesmo texto
### Aproveitando ao máximo a renderização de texto
* Coloque qualquer texto que precise aparecer na imagem entre aspas dentro do seu prompt
* Especifique o estilo da fonte se importar: "sans-serif", "handwritten", "bold uppercase"
* Para layouts densos de texto como pôsteres ou diagramas, divida o layout em seções claras no seu prompt
# Exemplos
`A photorealistic night scene on a narrow Barcelona street, warm amber streetlights , Gothic Quarter architecture lining both sides. In the foreground, a small tapas stall with a glowing sign reading "EL RACÓ" in bold yellow letters, a handwritten menu board underneath listing "Patatas Bravas, Croquetas, Pan con Tomate." Locals and tourists passing by, neon signs in Spanish and Catalan in the background.`
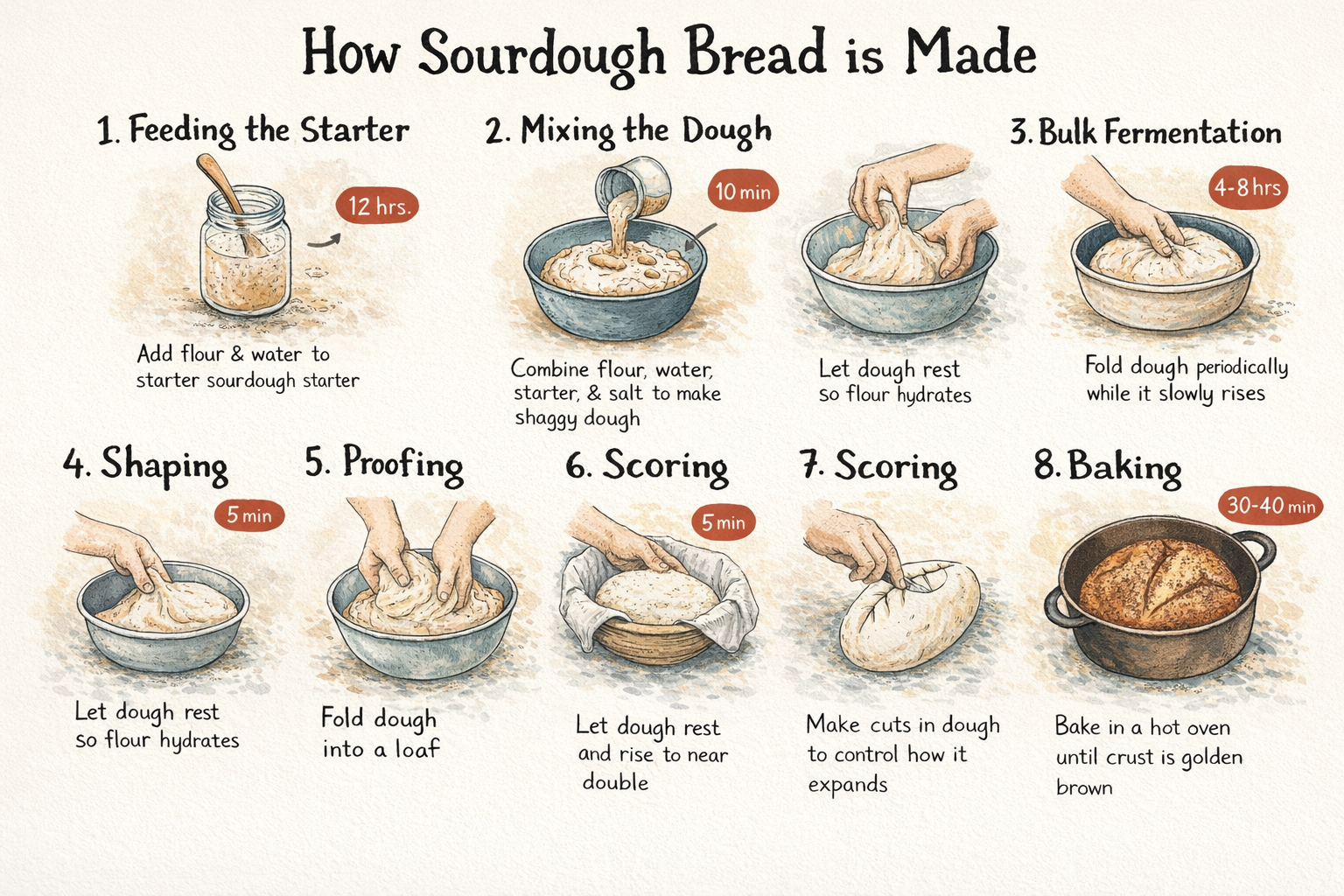
 ## Infográficos
O ChatGPT 1.5 é um dos modelos mais fortes da Krea para geração de infográficos. Diferente da maioria dos modelos que simplesmente coloca texto sobre uma imagem, ele raciocina sobre hierarquia, espaçamento e organização visual, entendendo a relação entre conteúdo escrito e layout em nível estrutural. Combinado com sua renderização precisa de texto denso, ele consegue receber um prompt complexo com múltiplas seções e retornar algo que parece pensado em vez de aproximado.
`A step-by-step process infographic titled "How Sourdough Bread is Made," showing 8 stages from starter to finished loaf — feeding the starter, mixing the dough, autolyse, bulk fermentation, shaping, proofing, scoring, and baking — each with a small hand-drawn style illustration and a time indicator. Warm cream background, hand-lettered headings, rustic editorial feel.`
## Infográficos
O ChatGPT 1.5 é um dos modelos mais fortes da Krea para geração de infográficos. Diferente da maioria dos modelos que simplesmente coloca texto sobre uma imagem, ele raciocina sobre hierarquia, espaçamento e organização visual, entendendo a relação entre conteúdo escrito e layout em nível estrutural. Combinado com sua renderização precisa de texto denso, ele consegue receber um prompt complexo com múltiplas seções e retornar algo que parece pensado em vez de aproximado.
`A step-by-step process infographic titled "How Sourdough Bread is Made," showing 8 stages from starter to finished loaf — feeding the starter, mixing the dough, autolyse, bulk fermentation, shaping, proofing, scoring, and baking — each with a small hand-drawn style illustration and a time indicator. Warm cream background, hand-lettered headings, rustic editorial feel.`
 ## **Cenas complexas**
Composições multielemento com relações espaciais específicas, interações entre sujeitos e detalhes ambientais em camadas.
`A busy Berlin market hall at 5am, three vendors in rubber aprons arranging fresh fish on crushed ice in the foreground, a fourth vendor mid-negotiation with a restaurant buyer in the middle ground, wooden crates stacked to the left, hanging overhead lights casting warm pools of yellow light across wet concrete floors, steam rising from a small food cart in the background selling hot broth to early morning workers, exposed iron roof structure and brick walls characteristic of a 19th century German markthalle visible above, depth of field pulling focus from the foreground vendors to the hazy activity behind, photorealistic, shot on 35mm.`
## **Cenas complexas**
Composições multielemento com relações espaciais específicas, interações entre sujeitos e detalhes ambientais em camadas.
`A busy Berlin market hall at 5am, three vendors in rubber aprons arranging fresh fish on crushed ice in the foreground, a fourth vendor mid-negotiation with a restaurant buyer in the middle ground, wooden crates stacked to the left, hanging overhead lights casting warm pools of yellow light across wet concrete floors, steam rising from a small food cart in the background selling hot broth to early morning workers, exposed iron roof structure and brick walls characteristic of a 19th century German markthalle visible above, depth of field pulling focus from the foreground vendors to the hazy activity behind, photorealistic, shot on 35mm.`
 ## Instruções explícitas de edição
O ChatGPT Image 1.5 é significativamente melhor em seguir instruções diretas de edição de imagem. Você agora pode tratar prompts como pedidos precisos de mudança em vez de redescrever a imagem inteira.
`Edit the uploaded image. Remove the person in the background on the left in the pink shirt. Keep the lighting unchanged. Preserve facial identity and skin texture of the main subjects. Maintain original camera angle and depth of field.`
## Instruções explícitas de edição
O ChatGPT Image 1.5 é significativamente melhor em seguir instruções diretas de edição de imagem. Você agora pode tratar prompts como pedidos precisos de mudança em vez de redescrever a imagem inteira.
`Edit the uploaded image. Remove the person in the background on the left in the pink shirt. Keep the lighting unchanged. Preserve facial identity and skin texture of the main subjects. Maintain original camera angle and depth of field.`

