Panoramica
L’ultimo modello di generazione di immagini di OpenAI, costruito su GPT Image 1.5, un’architettura nativamente multimodale che elabora testo e immagini attraverso un’unica rete unificata anziché trattarli come sistemi separati. Il risultato pratico è un modello che segue istruzioni complesse con una precisione insolita, gestisce il rendering di testo denso in modo accurato e apporta modifiche mirate alle immagini senza destabilizzare tutto il resto dell’inquadratura. È più lento e richiede più crediti rispetto ai Fast Models, ma per compiti che richiedono un’aderenza esatta al prompt, testo leggibile all’interno delle immagini o editing iterativo controllato, è una delle opzioni più capaci sulla piattaforma.Per iniziare
- Vai su Image Generation — Vai su krea.ai/image e seleziona questo modello dal menu a tendina.
- Seleziona ChatGPT 1.5 — Apri il selettore dei modelli e scegli ChatGPT 1.5 dalla sezione Intelligent Models.
- Scrivi il tuo prompt — Sii il più specifico e descrittivo possibile. ChatGPT 1.5 è costruito per seguire istruzioni precise, quindi prompt dettagliati producono risultati notevolmente migliori di quelli vaghi.
- Aggiungi immagini di riferimento (opzionale) — Carica immagini per guidare composizione, stile o soggetto.
- Scegli il tuo rapporto d’aspetto — Seleziona verticale, orizzontale o quadrato a seconda del tuo caso d’uso.
- Genera — Fai clic su Generate. ChatGPT 1.5 è più lento dei modelli veloci, ma la qualità dell’output riflette il tempo di elaborazione aggiuntivo.
- Itera — Chiedi modifiche specifiche al tuo risultato. ChatGPT 1.5 modificherà solo ciò che chiedi mantenendo il resto dell’immagine coerente.
In sintesi
| Caratteristica | Dettaglio |
|---|---|
| Velocità | Lento (1/3) |
| Crediti | ~150 per generazione |
| Modello sottostante | GPT Image 1.5 (OpenAI) |
| Ideale per | Prompt complessi, rendering del testo, editing preciso |
| Dimensioni supportate | 1:1 quadrato, 3:2 orizzontale, 2:3 verticale |
| Supporto style reference | Sì |
Quando usare ChatGPT 1.5
ChatGPT 1.5 è il modello giusto a cui rivolgersi quando la precisione conta più della velocità. La sua architettura nativamente multimodale significa che comprende la relazione tra testo e immagine a un livello più profondo rispetto alla maggior parte dei modelli, il che si traduce in una maggiore aderenza al prompt e risultati più affidabili su richieste complesse o stratificate. La sua capacità di rendering del testo è particolarmente forte. Dove molti modelli faticano a produrre testo leggibile e correttamente ortografato all’interno di un’immagine, ChatGPT 1.5 gestisce testo denso e in piccola scala in modo accurato, rendendolo una scelta solida per qualsiasi prompt che includa insegne, tipografia, etichette o diagrammi. Eccelle anche nell’editing iterativo. Quando gli chiedi di cambiare una cosa specifica in un’immagine, regola solo ciò che hai specificato preservando somiglianza facciale, illuminazione, composizione e tono del colore nel resto dell’inquadratura. Questo affronta una delle frustrazioni più comuni con la generazione di immagini AI, dove chiedere una piccola modifica provoca la rigenerazione dell’intera immagine da zero.| Usa quando | Evita quando |
|---|---|
| Il tuo prompt è complesso e richiede un’interpretazione precisa | Ti servono risultati rapidi o sei in fase di bozza |
| La tua immagine deve includere testo leggibile | Hai un budget di crediti ridotto |
| Devi fare modifiche specifiche senza cambiare l’intera immagine | Vuoi un output fortemente stilizzato o artistico |
| Stai lavorando su diagrammi, personaggi o scene dettagliate | Ti serve supporto per gli stili LoRA |
| Contano somiglianza facciale o coerenza visiva tra le modifiche |
Casi d’uso comuni
- Diagrammi e infografiche: illustrazioni tecniche con etichette e testo accurati
- Character design: aspetto coerente del personaggio in più iterazioni
- Visual di marketing: layout con copy leggibile, loghi o callout di prodotto
- Photo editing: modifiche mirate a immagini esistenti senza rigenerazione completa
- Scene complesse: composizioni multi-elemento che richiedono relazioni spaziali precise
Suggerimenti sui prompt
Scrivere prompt efficaci
- Scrivi i prompt come daresti un brief creativo dettagliato — descrivi esplicitamente soggetto, stile, illuminazione, composizione e mood
- Per il testo all’interno delle immagini, specifica esattamente il wording, lo stile del font, la dimensione e la posizione
- Descrivi chiaramente le relazioni spaziali: “una tazza rossa sul lato sinistro di un tavolo bianco, luce dalla finestra a destra”
- ChatGPT 1.5 gestisce bene prompt lunghi e dettagliati — non abbreviare quando puoi essere specifico
Iterare sui risultati
- Quando modifichi, descrivi solo il cambiamento che vuoi e lascia tutto il resto non specificato — il modello preserverà ciò che non menzioni
- Per il lavoro sui personaggi, stabilisci l’aspetto nella prima generazione e poi richiamalo esplicitamente nelle modifiche successive
- Se il risultato non è del tutto giusto, affina il linguaggio del prompt anziché rigenerare con lo stesso testo
Ottenere il massimo dal rendering del testo
- Metti qualsiasi testo che desideri nell’immagine tra virgolette all’interno del tuo prompt
- Specifica lo stile del font se conta: “sans-serif”, “scritto a mano”, “maiuscolo grassetto”
- Per layout di testo denso come poster o diagrammi, suddividi il layout in sezioni chiare nel tuo prompt
Esempi
A photorealistic night scene on a narrow Barcelona street, warm amber streetlights , Gothic Quarter architecture lining both sides. In the foreground, a small tapas stall with a glowing sign reading "EL RACÓ" in bold yellow letters, a handwritten menu board underneath listing "Patatas Bravas, Croquetas, Pan con Tomate." Locals and tourists passing by, neon signs in Spanish and Catalan in the background.

Infografiche
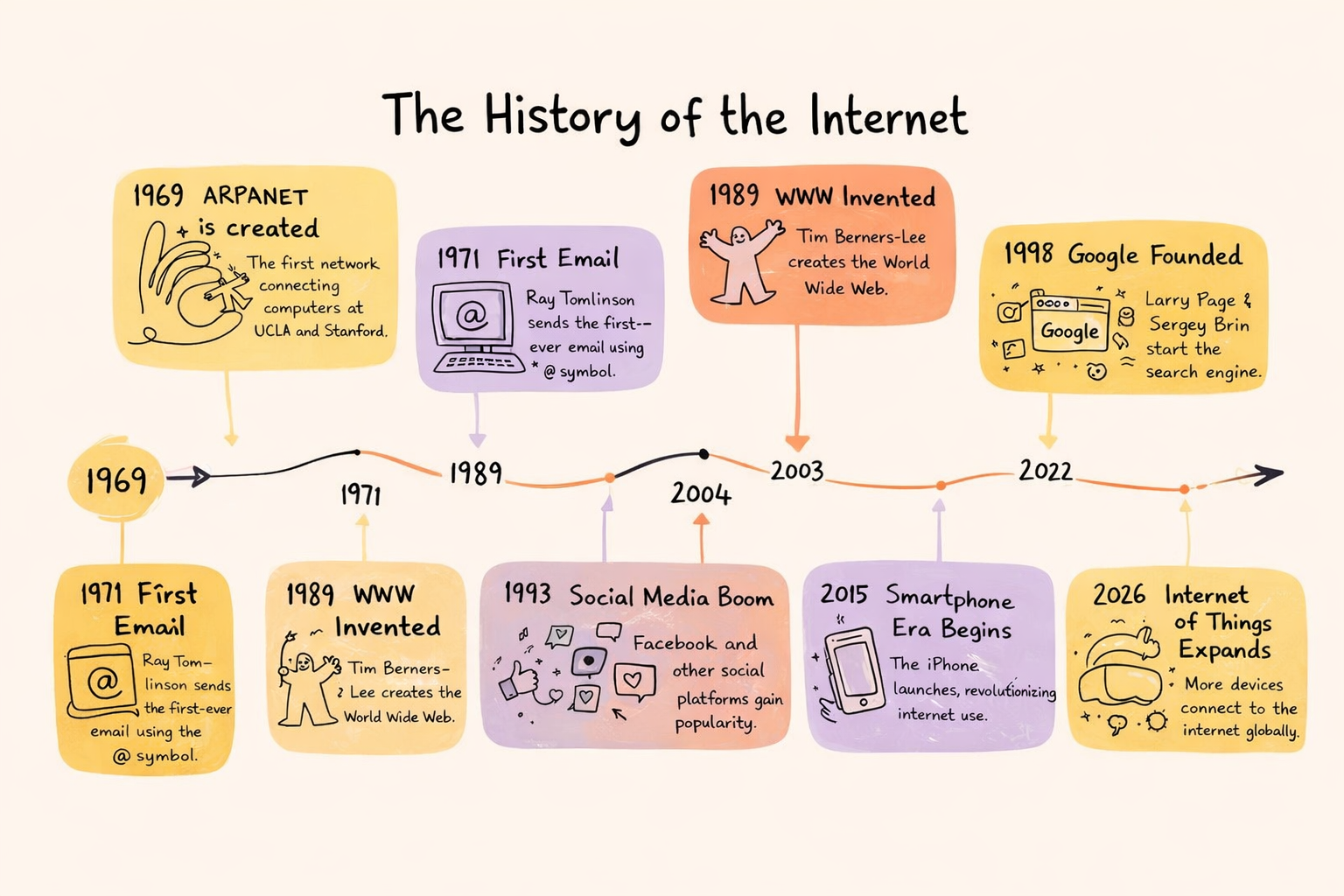
ChatGPT 1.5 è uno dei modelli più forti su Krea per la generazione di infografiche. A differenza della maggior parte dei modelli che semplicemente inseriscono testo su un’immagine, ragiona su gerarchia, spaziatura e organizzazione visiva, comprendendo la relazione tra contenuto scritto e layout a livello strutturale. Combinato con il suo rendering accurato di testo denso, può prendere un prompt complesso multi-sezione e restituire qualcosa che sembra ponderato anziché approssimativo.A step-by-step process infographic titled "How Sourdough Bread is Made," showing 8 stages from starter to finished loaf — feeding the starter, mixing the dough, autolyse, bulk fermentation, shaping, proofing, scoring, and baking — each with a small hand-drawn style illustration and a time indicator. Warm cream background, hand-lettered headings, rustic editorial feel.
Scene complesse
Composizioni multi-elemento con relazioni spaziali specifiche, interazioni tra soggetti e dettagli ambientali stratificati.A busy Berlin market hall at 5am, three vendors in rubber aprons arranging fresh fish on crushed ice in the foreground, a fourth vendor mid-negotiation with a restaurant buyer in the middle ground, wooden crates stacked to the left, hanging overhead lights casting warm pools of yellow light across wet concrete floors, steam rising from a small food cart in the background selling hot broth to early morning workers, exposed iron roof structure and brick walls characteristic of a 19th century German markthalle visible above, depth of field pulling focus from the foreground vendors to the hazy activity behind, photorealistic, shot on 35mm.

Istruzioni esplicite di modifica
ChatGPT Image 1.5 è significativamente migliore nel seguire istruzioni dirette di modifica delle immagini. Ora puoi trattare i prompt come richieste di modifica precise anziché ri-descrivere l’intera immagine.Edit the uploaded image. Remove the person in the background on the left in the pink shirt. Keep the lighting unchanged. Preserve facial identity and skin texture of the main subjects. Maintain original camera angle and depth of field.

