概要
OpenAI 最新の画像生成モデルで、テキストと画像を別々のシステムとして扱うのではなく、単一の統一ネットワークを通じて処理するネイティブなマルチモーダルアーキテクチャ GPT Image 1.5 に基づいています。実用面では、複雑な指示を非常に精密に遵守し、濃密なテキストレンダリングを正確に扱い、フレームの他の部分を不安定にすることなく画像にターゲットを絞った編集を加えるモデルとなっています。 Fast Models よりも遅く、より多くのクレジットを消費しますが、正確なプロンプト遵守、画像内の読みやすいテキスト、制御された反復的な編集を必要とするタスクに関して、プラットフォーム上で最も高機能な選択肢の 1 つです。はじめに
- 画像生成へ移動 — krea.ai/image に移動し、ドロップダウンからこのモデルを選択します。
- ChatGPT 1.5 を選択 — モデルピッカーを開き、Intelligent Models セクションから ChatGPT 1.5 を選びます。
- プロンプトを書く — できるだけ具体的で詳細に書きましょう。ChatGPT 1.5 は精密な指示の遵守に向けて構築されているため、詳細なプロンプトは曖昧なものよりもはるかに良い結果を生みます。
- 参照画像を追加する (オプション) — 構図、スタイル、被写体を導くために画像をアップロードします。
- アスペクト比を選ぶ — 用途に応じてポートレート、ランドスケープ、正方形を選択します。
- 生成 — Generate をクリックします。ChatGPT 1.5 は高速モデルよりも遅いですが、出力品質は追加の処理時間を反映しています。
- 反復 — 結果に対して特定の変更を依頼します。ChatGPT 1.5 は依頼した部分のみを変更し、残りの画像は一貫性を保ちます。
概要
| 特徴 | 詳細 |
|---|---|
| 速度 | 遅い (1/3) |
| クレジット | 生成あたり約 150 |
| 基盤モデル | GPT Image 1.5 (OpenAI) |
| 得意分野 | 複雑なプロンプト、テキストレンダリング、精密な画像編集 |
| サポートサイズ | 1:1 正方形、3:2 ランドスケープ、2:3 ポートレート |
| スタイル参照サポート | あり |
ChatGPT 1.5 を使うタイミング
ChatGPT 1.5 は、速度よりも精度が重要な場合に選ぶべきモデルです。ネイティブなマルチモーダルアーキテクチャにより、ほとんどのモデルよりも深いレベルでテキストと画像の関係を理解し、複雑または多層的なリクエストに対してより強いプロンプト遵守とより信頼できる結果につながります。 テキストレンダリング能力は特に強力です。多くのモデルが画像内で読める、正しく綴られたテキストを生成するのに苦労するのに対し、ChatGPT 1.5 は濃密で小さなスケールのテキストも正確に処理するため、サイネージ、タイポグラフィ、ラベル、ダイアグラムを含むプロンプトに堅実な選択肢となります。 反復編集にも優れています。画像内の特定の 1 点を変更するよう依頼すると、指定した部分のみを調整しながら、顔の類似性、ライティング、構図、色調をフレームの他の部分で保持します。これは AI 画像生成で最もよくある不満の 1 つ、つまり小さな編集を依頼すると画像全体がゼロから再生成されてしまう問題に対処するものです。| 使用するとき | 避けるとき |
|---|---|
| プロンプトが複雑で、精密な解釈が必要 | 高速な結果が必要、または初期のドラフト段階 |
| 画像に読みやすいテキストが必要 | クレジットの予算が厳しい |
| 画像全体を変えずに特定の編集を行う必要がある | 強くスタイライズされたまたは芸術的な出力が欲しい |
| ダイアグラム、キャラクター、詳細なシーンを扱っている | LoRA スタイルのサポートが必要 |
| 顔の類似性や編集間のビジュアルの一貫性が重要 |
一般的な使用例
- ダイアグラムとインフォグラフィック: 正確なラベルとテキストを含む技術イラストレーション
- キャラクターデザイン: 複数の反復で一貫したキャラクター外観
- マーケティングビジュアル: 読めるコピー、ロゴ、製品コールアウトを含むレイアウト
- 写真編集: 完全な再生成を伴わない、既存画像へのターゲットを絞った変更
- 複雑なシーン: 精密な空間関係を必要とするマルチ要素の構図
プロンプトのヒント
効果的なプロンプトの書き方
- 詳細なクリエイティブブリーフを渡すようにプロンプトを書く — 被写体、スタイル、ライティング、構図、ムードを明示的に説明する
- 画像内のテキストは、正確な文言、フォントスタイル、サイズ、配置を指定する
- 空間関係を明確に説明する: 「白いテーブルの左側に赤いマグカップ、右側から窓の光」
- ChatGPT 1.5 は長く詳細なプロンプトをよく扱う — 具体的にできるところで省略しない
結果の反復
- 編集の際は、変更したい部分のみを説明し、それ以外は指定しない — モデルは指定しなかった部分を保持する
- キャラクター作業では、最初の生成で外観を確立し、その後の編集で明示的に参照する
- 結果が完全に正しくない場合は、同じテキストで再生成するのではなく、プロンプトの言い回しを洗練する
テキストレンダリングを最大限に活用する
- 画像に必要なテキストはプロンプト内で引用符に入れる
- 重要な場合はフォントスタイルを指定する: 「sans-serif」「handwritten」「bold uppercase」
- ポスターやダイアグラムなどの濃密なテキストレイアウトの場合、プロンプト内でレイアウトを明確なセクションに分ける
例
A photorealistic night scene on a narrow Barcelona street, warm amber streetlights , Gothic Quarter architecture lining both sides. In the foreground, a small tapas stall with a glowing sign reading "EL RACÓ" in bold yellow letters, a handwritten menu board underneath listing "Patatas Bravas, Croquetas, Pan con Tomate." Locals and tourists passing by, neon signs in Spanish and Catalan in the background.

インフォグラフィック
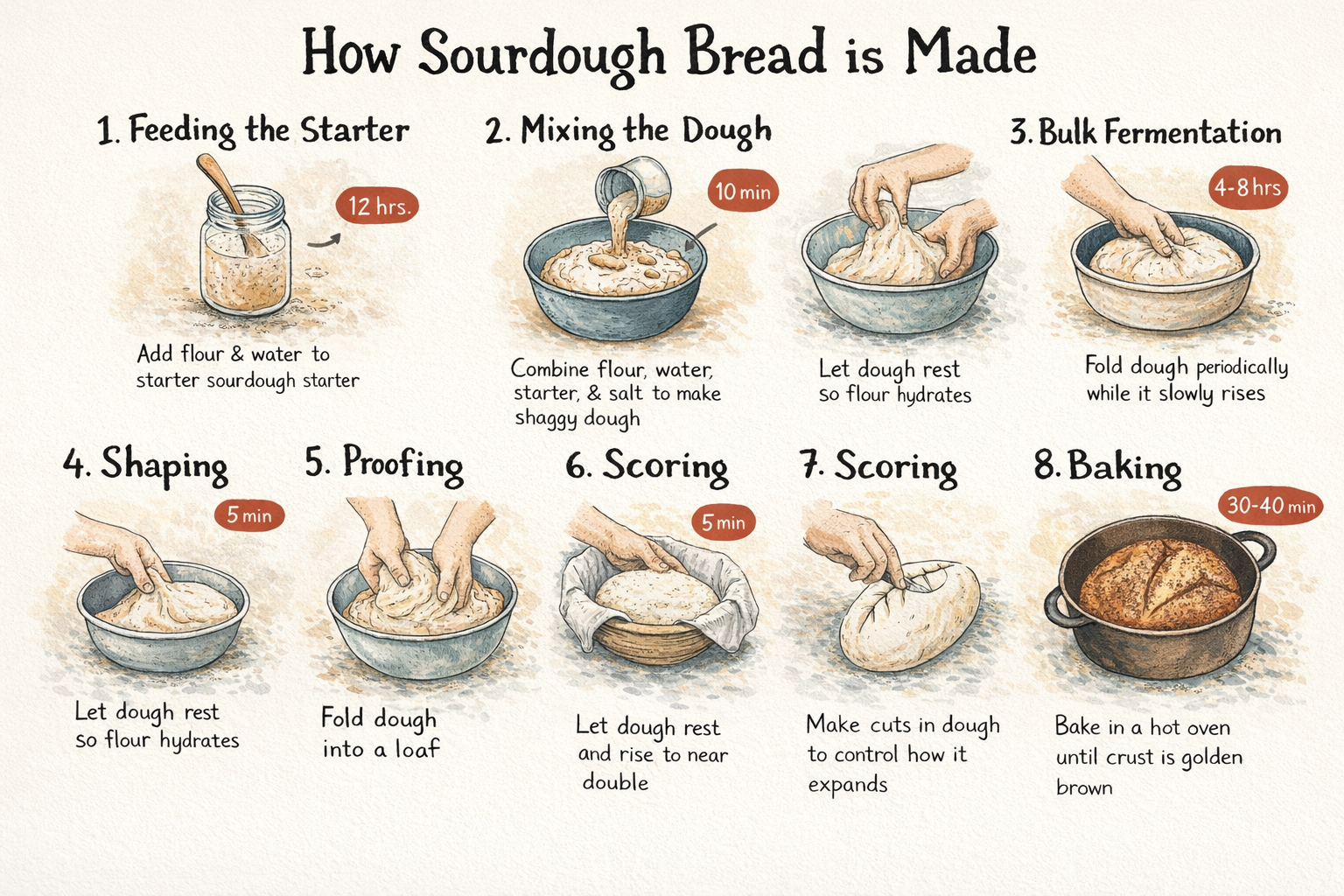
ChatGPT 1.5 は、Krea 上のインフォグラフィック生成において最も強力なモデルの 1 つです。ほとんどのモデルが単にテキストを画像上に配置するだけであるのに対し、階層、間隔、視覚的な整理について推論し、書かれたコンテンツとレイアウトの関係を構造的なレベルで理解します。正確な濃密テキストレンダリングと組み合わせると、複雑な複数セクションのプロンプトを受け取り、近似ではなく、考え抜かれたように見える結果を返せます。A step-by-step process infographic titled "How Sourdough Bread is Made," showing 8 stages from starter to finished loaf — feeding the starter, mixing the dough, autolyse, bulk fermentation, shaping, proofing, scoring, and baking — each with a small hand-drawn style illustration and a time indicator. Warm cream background, hand-lettered headings, rustic editorial feel.
複雑なシーン
特定の空間関係、被写体間の相互作用、レイヤー化された環境の詳細を持つマルチ要素の構図。A busy Berlin market hall at 5am, three vendors in rubber aprons arranging fresh fish on crushed ice in the foreground, a fourth vendor mid-negotiation with a restaurant buyer in the middle ground, wooden crates stacked to the left, hanging overhead lights casting warm pools of yellow light across wet concrete floors, steam rising from a small food cart in the background selling hot broth to early morning workers, exposed iron roof structure and brick walls characteristic of a 19th century German markthalle visible above, depth of field pulling focus from the foreground vendors to the hazy activity behind, photorealistic, shot on 35mm.

明示的な編集指示
ChatGPT Image 1.5 は、画像編集の直接指示に従うことが大幅に得意になりました。画像全体を再説明する代わりに、プロンプトを精密な変更依頼として扱えるようになりました。Edit the uploaded image. Remove the person in the background on the left in the pink shirt. Keep the lighting unchanged. Preserve facial identity and skin texture of the main subjects. Maintain original camera angle and depth of field.

